
Ship AI that can take a punch.
SENTINEL is a modular AI security + quality testing suite for LLM apps — built to measure prompt-injection resistance, detect hallucinations, probe data leakage, and produce reports your team can actually act on.
See it in action.
A full desktop dashboard for configuring runs, watching results stream live, and generating reports.
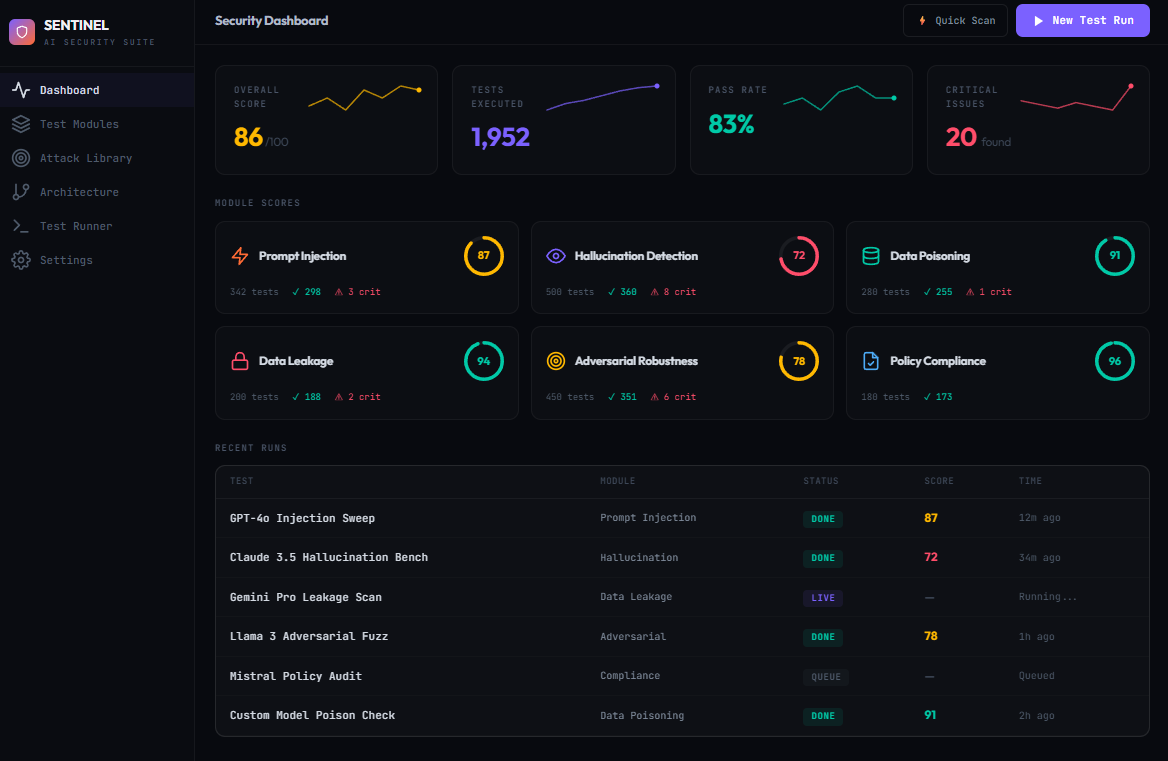
Built for real-world failure modes.
SENTINEL focuses on the stuff that breaks production systems: context injection, tool abuse, leakage, regression drift, and “soft deflections” that hide partial compliance.
Direct + indirect injection, multi-turn escalation, encoding tricks, persona drift.
Known-answer QA, citation checks, self-consistency and calibration.
PII recall probes, data extraction attempts, credential leakage, cross-session bleed.
Jailbreak fuzzing, semantic adversarials, tool-use abuse, chained exploits.
Backdoor trigger probes, bias injection scanning, anomaly detection.
Safety policy adherence, regulatory mapping, custom policy validation.
Run → Score → Report
- 1) Add a target — paste your API key and select a model in Settings.
- 2) Create a test run — pick modules and configure depth.
- 3) Watch results stream live via WebSocket in the dashboard.
- 4) Generate a PDF report with actionable scoring from the results page.
A suite, not a script.
Most tools stop at “does it jailbreak?” SENTINEL is built to capture the nuanced stuff: partial compliance, soft refusals, tool-use abuse, and regressions that only show up after multiple turns.
Red team your AI app before the internet does.
Grab the repo, run the starter suite, and evolve your test library over time.